

AI model costs can explode fast – and overpaying is common. The reality is, you don’t need GPT-4 for most business tasks like customer support, summarization, or data extraction. Switching to smaller AI models, smart routing, and techniques like RAG, caching, and prompt optimization, can cut GenAI costs by 10× or more. Done correctly, you can also preserve up to ~80% of performance.
This guide explains five practical strategies – model routing, prompt engineering, fine-tuning, retrieval, caching – to help you achieve cost-effective GenAI. Plus, learn a simple decision framework to apply them. By the end, you’ll know how to match model power to task needs so your AI project stays both high-quality and budget-friendly.
Imagine you just launched an AI feature using OpenAI’s GPT-4. At first, it worked perfectly. But in the second week after launch, the cloud bill arrived…alongside a call from the Chief Financial Officer. Every query to GPT-4 comes with a real, if small, price tag.
The cost problem – and why choosing the right AI model for the job is important
Processing 10,000 customer-support tickets, each with 500 tokens of input and 200 tokens of output, costs about $16 on GPT-4.1 (the latest and greatest version). However, it’s only $3.20 on the smaller “GPT-4.1 mini” model – and a drastically less $0.80 using an even smaller model.
In other words, choosing the right model changes expenses by an order of magnitude. This is a classic case of the “AI feature turned expensive” trap. But the truth is, we probably don’t need the most elite model. In effect, you can get about 80 percent of GPT-4’s performance for about 20 percent of the cost.
Why are the top AI models overkill for most tasks?
To put this into perspective, GPT-4 (8K context) costs about $2.00 per 1 million input tokens, and $8.00 per 1 million output tokens. Therefore, even though GPT-4 and other frontier models are making great strides in what they can accomplish, they are costly per token.
Smaller models are, of course, far more affordable. For example, “GPT-4o-mini” costs only about $0.15/$0.60 per million tokens. The budget Anthropic model, Claude 3 Haiku, runs around $0.25/$1.25 per million, and even a large Llama 3 model (hosted via API) is in the order of $0.70–0.90 per million.
In reality, most enterprise tasks don’t need GPT-4’s full capabilities. Classification, data extraction, basic summarization, and FAQs are all within the capabilities of much smaller LLMs.
One analysis has framed this as an 80/20 rule: roughly 60% of typical tasks, which it calls Tier 1 use cases, can be performed by small models of 7 billion to 14 billion parameters.
Adding in moderately complex tasks (Tier 2, another ~20%) still only requires mid-sized models (30–70B) – often with retrieval augmentation. It’s only the final ~20% of cases (Tier 3) truly demand a GPT-4–class model.
The PE Collective pointed out that “GPT.-4-class reasoning models … consume more tokens internally, and are not cost-effective for simple classification or extraction tasks”. Likewise, Anthropic’s mid-tier Claude Sonnet can deliver about 80% of GPT-4’s quality at 20% of the cost.
In short: don’t use GPT-4 for everything. High prices mean that using small or mid-tier models (plus smart techniques) is usually the better 80/20 tradeoff for routine business tasks.
5 ways to reduce the cost of GenAI
Here are five ways companies can lower GenAI costs. I’ll explain what they are, when and how to use them, and the approximate savings you might expect.
We use concrete examples where possible – e.g., how a prompt refinement decreased tokens from 1429 to 418 – and we’ll also call out key ‘gotchas’ to watch.
The five ways to lower GenAI costs we’ll explore are:
• Model Tiering (Multi-Model Routing): Route by complexity.
• Prompt Engineering: Craft tight prompts to cut tokens.
• Fine-Tuning: Specialize small models on your data.
• Retrieval-Augmented Generation (RAG): Retrieve context instead of huge input.
• Caching & Batching: Reuse answers and group calls for scale.
Simple Talk is brought to you by Redgate Software
How to reduce AI cost with model tiering (multi-model routing)
Route most queries to the cheapest capable model using a simple LLM “router,” and reserve GPT-4 for only the hardest ~10–20%. This will drastically cut costs with minimal overhead.
For those who don’t need the full power of GPT-4, it’s often better to ‘tier’ queries – routing them to the cheapest model that can answer them. What this looks like in practice is creating a simple “router” LLM (or classifier), which assesses a query’s intent or complexity. It’ll then choose where to send it to: either a small, cheap model, or the big, expensive GPT-4.
For example: a lightweight classifier that tags queries as “FAQ vs. Analysis/simple queries” and sends FAQ questions to a small model or Microsoft Knowledge Base (KB) search. Meanwhile, legal analysis questions are sent to GPT-4.
You should (almost) always take this approach once you have more than 100 queries. It adds very little overhead yet drastically shrinks your token bill. In practice, Tier 3 (frontier) models are only needed for around 10–20% of queries.
What are some real-world examples of the cost savings?
In one enterprise rollout, this traffic routing method cut large language model (LLM) spend by 35–55%. 60% of traffic was routed to a cheap model, 30% to a medium model, and 10% to a large one.
Further analysis found that if user questions were routed to GPT-4 only 40-60% of the time, the blended cost of serving all queries using the mixture of experts’ technique was a fraction of the cost of only using GPT-4. Simply put: if only 20% of queries use GPT-4, your blended cost plummets proportionally.
For example, at my company, we were working on a project involving 10,000+ user queries a month. We initially passed all of the queries through a large model, the costs of which rapidly grew beyond our projections. So, on our second attempt, we introduced a simple routing layer. With this in place, the expensive large model was used for less than 20% of our queries – and our overall costs were nearly halved (50%).
To make this work, however, you’ll first need to invest in the complexity of building the router. When you do so, you should also log results per/router/tier, and set confidence thresholds (i.e., if the small model’s prediction seems iffy, route up). You’ll also need to watch out for the classifier mistakenly marking a hard query as ‘easy’, as this is where output quality can suffer.
It’s also worth running a small, fast model first, to assess the quality of its answer. If the answer has low confidence, you can simply re-run GPT-4 as a fallback. Furthermore, watch latency – adding steps can slow responses, so use async calls or batch where possible.
How to use prompt engineering to reduce the costs of AI
The key is to write good prompts. Be precise about the format you’re looking for, eliminate wordiness, and keep your directions and context short. A well-crafted prompt can elicit the same response from a small model that a sloppy prompt would need GPT-4 for – and each extra word in a prompt costs tokens. This means: make instructions concise, specify desired format, remove fluff, and trim context.
Of course, the more refined prompt could lead to less output than the less refined prompt. Yet, it’s always good practice to focus on prompt refinement before defaulting to using a larger AI model. For example, instead of “explain this code to me in detail in simple terms,” you might use “in one sentence each, list what the following Python functions do.” That alone can shrink output needs.
Studies have shown that such iterative prompt fixes can result in a 50–85% saving of tokens (and therefore dollars), without changing AI models. This cost saving is dramatic.
Real-world examples of prompt engineering reducing the cost of AI
In one experiment, we reduced a verbose instruction from 500 down to 200 tokens. We then asked for a structured JSON output instead of free text, which saved another 50-60%. Finally, by eliminating the examples in the prompt (if the model can handle it), we saved an additional 85%.
Full GPT-4, meanwhile, will take a 10-step prompt that was displayed as a bullet point list, and write it out in a paragraph of text instead.
For example, a “low-rent” version might be:
“You are a helpful assistant. Here is a paragraph of text… [500 tokens of system prompt] … now answer the question.”
Whereas an optimized version would be:
“Summarize the key points of the following paragraph in 2-3 sentences: “[your text]”.
In trials, this kind of tightening can reduce prompt and answer length by over half.
So, just remember: a vague prompt or a short prompt might confuse the model. On the other hand, over-engineered prompts are more brittle. Always test that the shorter prompt still elicits correct output. And, consider that prompt-tweaking costs time. Sometimes a slightly larger model is cheaper overall than endless prompt tweaks.
Fine-tuning on domain data to reduce the cost of AI usage
Another approach is to use a much smaller model instead of GPT-4, and ‘train’ it on your own data. Smaller models include 7B or 13B Llama, Mistral, or Qwen. The smaller open model is then fine-tuned with examples from your domain – whether that’s customer tickets, internal documents, code, or something else. The result is a model that is an ‘expert’ on your content.
Fine-tuning works well when you have a well-scoped task and sufficient training data. It’s especially useful when your data is proprietary or sensitive. Common use cases include customer support, code assistants, and internal documentation Q&A.
One person I spoke to fine-tuned a 7–9B parameter model on math grading, and the resulting model outperformed GPT-4 on that task. Another study found that among 10 small models (6–10B), six outperformed GPT-4 on benchmark tasks after fine-tuning. Small models also require far less compute, reducing both cost and latency. A 7B fine-tuned model, for example, can cost roughly 10× less per token than GPT-4.
The cost savings can be substantial. One startup CEO reported reducing their GPT-4 bill from $47,000 per month to around $500 by switching to a fine-tuned model. This is because each response is significantly cheaper — for example, a fine-tuned Llama model may cost a fraction of GPT-4 per 1,000 tokens for both input and output.
That said, fine-tuning comes with overhead. You need high-quality training data, a pipeline to manage training and deployment, and infrastructure to host the model. It’s also important to include a validation step — comparing the tuned model against the base model and GPT-4 on new data — and to watch for issues like catastrophic forgetting.
Subscribe to the Simple Talk newsletter
Retrieval-augmented generation (RAG) for reducing AI usage costs
An alternative to stuffing huge documents into GPT-4 is a technique called Retrieval-Augmented Generation (RAG). Let’s say you need an answer from a 50-page manual. RAG works well when many queries are expected, such as question answering over document sets, intranets, or codebases. It’s especially useful for large or changing knowledge bases where the goal is to reduce token usage.
The cost savings become dramatic for larger documents. For example, Anthropic notes that a 1 million-token context can cost about $15 per query. With RAG, only the most relevant 2,000–10,000 tokens are retrieved and sent to the model. The result? Cost is cut by around 50 to 200 times, to roughly $0.10–$0.30 per query. Answer quality may also be improved, since focusing on relevant context increases the signal-to-noise ratio.
For example, a team I worked with had a 10,000-page technical specification. Calling GPT-4 on the entire document would cost thousands per query. With RAG, the documents are embedded and indexed, and only the top few relevant chunks are retrieved per query. In one benchmark, this approach achieved about 90% of the retrieval quality at roughly 1/100th of the token cost.
However, RAG is not always the right choice. Tasks that require full-document reasoning – such as identifying subtle contradictions across sections, or debugging interconnected code – may perform better with long-context models. RAG pipelines also introduce complexity, requiring document chunking, a vector database, and good embeddings.
In practice, many systems use a hybrid approach: RAG to narrow context, followed by a larger-context model for final synthesis.
You may also be interested in…
Why most enterprise AI projects fail – and how to fix them
Using caching and batching to reduce AI usage costs
Two strategies to reduce the per-query cost of using AI/large language models (LLMs) are caching and batching. Caching means storing previous LLM responses (or chunks of them), allowing repeated or similar queries to hit the cache. Batching means bundling multiple independent requests into a single API request.
Batching is best for non-real-time workloads. Most major LLM providers (like OpenAI or Anthropic) also automatically cache static prompt context (e.g., system prompts or knowledge bases).
The cost saving of both approaches is significant. Even a 20% cache hit rate reduces LLM usage by that fraction, while more advanced semantic caching can cut 40–70% of calls in repetitive scenarios. Cached input tokens often cost up to 90% less, meaning a large system prompt may only be paid for once and then reused where necessary.
Many LLMs also offer batch APIs, where combining multiple requests into a single call reduces overhead and cost per completion. In informal tests, grouping 10 small completions into one call can yield up to ~5–10× cost reduction.
For example, if you have 10 documents to summarize (each ~500 tokens), sending them individually might cost $10 total. Batching them could reduce that to around $5.
Similarly, if a common query like “what are your hours?” is asked repeatedly, caching avoids repeated LLM calls entirely.
Batching does add latency, since you need to wait to accumulate requests, so it’s best suited for non-urgent workloads. Caching also requires careful management, including memory usage and cache invalidation, to avoid stale responses.
How to decide which approach is best for your use case: a simple decision framework
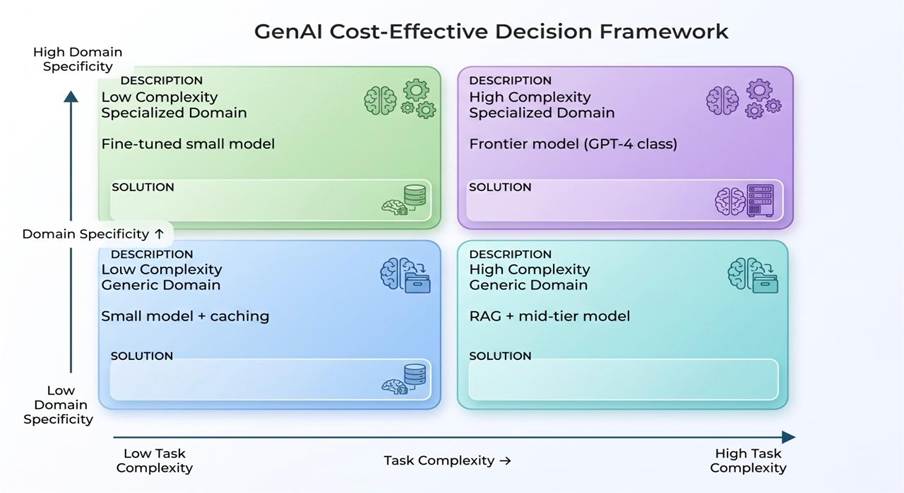
To tie this together, consider two dimensions: task complexity (low vs. high), and domain specificity (generic vs. specialized). We can use a 2×2 matrix to help guide our choice of approach, as outlined in the graph below. It’ll help ensure you’re not defaulting to the most expensive model for routine tasks.
As Dimitri Theodoropoulos and Mario Schietti, partners at McKinsey, said: “The best model isn’t always the most capable one — it’s the one that delivers required quality at sustainable cost.”
Which approach is best for lower-complexity AI tasks?
For lower complexity tasks such as simple Q&A or summarization, a small off-the-shelf model or a rule-based answer (for repetitive queries) can be used. Caching can cover repeated queries.
Additionally, for low-complexity, specialized domain tasks — such as a specific FAQ or narrow data extraction — fine-tuning a small model on your domain data can yield customized answers that are far cheaper than generic GPT.-4.
Which approach is best for high-complexity AI tasks?
For high complexity, generic domain use cases (think general RAG queries or multi-document synthesis), a multi-model pipeline is works well. This pipeline includes a fast path for RAG plus a mid-tier model (e.g., Claude Sonnet, GPT-4) with caching, and a slow path for escalation. Put simply: fast path = RAG + mid-model, slow path = escalate.
On the other hand, the high complexity, specialized domain quadrant is less commonly encountered. These tasks may include legal analysis or medical advice, and only a frontier model (for LLMs, think of a GPT-4, GPT-5 or Claude Opus) would likely do so safely. In practice, this quadrant is rare (~20% of cases).
When the 80/20 AI cost-saving rule does not work
20% of the time, we have to rely on the big model or new techniques to manage what’s known as the ‘hard cases.’ This is where the 80/20 rule does not apply. These ‘hard cases’ include creative tasks (like story writing), multi-step reasoning and problem solving, and reading complex legal documents.
Michael Hannecke of Unlikely AI describes these tasks as ‘tier 3’ – ‘open-ended creative tasks without clear structure.’ These tasks include making up slogans and writing stories – exactly where GPT-4’s wide-ranging knowledge and creativity can be a tremendous asset. Likewise, GPT-4 excels at tasks that involve multi-step reasoning, such as logical puzzles, and problem solving that requires planning.
These are also cases where the ability to read an entire book, codebase or legal contract is necessary. RAG won’t help if the insight only comes from the full context. In high-stakes domains (medical diagnosis, critical financial decisions, legal advice, etc.), we are willing to accept slower and more expensive inference in exchange for more accurate and vetted output.
Final thoughts
Overall, small models can’t do everything large models can do. They aren’t a panacea; they tend to hallucinate more and lack the depth of GPT-4. But where the cost of failure is high (patient safety, legal liability), it makes sense to use the best model regardless of cost.
For many teams, cost-efficiency in GenAI isn’t about whether to use it, but how. Practical judgment, paired with strategies like retrieval, caching, routing, prompt engineering, and fine-tuning – and above all matching model power to problem scope – puts the 80/20 sweet spot within reach. The real skill isn’t just finding the cheapest model, but identifying which tasks actually require the premium one.
“Everyone wants to move faster with AI, but few are truly ready for it.”
FAQs: How to cut AI usage costs
1. How can I reduce AI model costs quickly?
Use smaller models for simple tasks, reserve GPT-4 for complex queries, and apply routing, caching, and prompt optimization to cut costs immediately.
2. Do I really need GPT-4 for most business use cases?
No. Most tasks – like summarization, FAQs, and data extraction – can be handled by much cheaper small or mid-tier models of similar quality.
3. What is model routing in AI?
Model routing is a system that classifies queries by complexity and sends them to the cheapest suitable model, only escalating to GPT-4 when necessary.
4. How much can prompt engineering reduce costs?
Well-optimized prompts can reduce token usage by 50–85%, significantly lowering both input and output costs without changing models.
5. What is Retrieval-Augmented Generation (RAG)?
RAG reduces costs by retrieving only relevant information instead of sending large documents to the model, cutting token usage and improving efficiency.
6. Does caching actually save money in AI systems?
Yes. Caching repeated or similar queries can reduce API calls by 20–70%, dramatically lowering total LLM spend in production systems.
7. What is the best overall strategy to reduce GenAI costs?
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved



Load comments